通过将“隐私和安全”设置为不“不保护”之后确实可以关掉大部分网站下载时候的提示,但是经过Pop测试还是有像下载京东发票等的网站会阻止,提示不是安全的内容。
解决办法:
方法一:添加不安全内容网站通配符白名单
经Pop在Chrome 121.0.6167.86版本测试有效。
1、打开浏览器设置页面,点击 隐私和安全,进入 网站设置页面 Continue reading "去掉Chrome谷歌浏览器HTTP不安全的下载警告提醒(已阻止不安全下载)"
操作系统和网络技术研究
通过将“隐私和安全”设置为不“不保护”之后确实可以关掉大部分网站下载时候的提示,但是经过Pop测试还是有像下载京东发票等的网站会阻止,提示不是安全的内容。
解决办法:
方法一:添加不安全内容网站通配符白名单
经Pop在Chrome 121.0.6167.86版本测试有效。
1、打开浏览器设置页面,点击 隐私和安全,进入 网站设置页面 Continue reading "去掉Chrome谷歌浏览器HTTP不安全的下载警告提醒(已阻止不安全下载)"
问题:如果在 https 协议的页面中加载了 http 资源,浏览器将认为这是不安全的,会默认阻止,会带来资源不全的问题。就会导致图片无法显示,样式无法加载,JS 无法加载。如果页面关键资源均为 http 协议,所有的操作、请求都将无效。
解决办法:
1、直接复制位于http协议服务器上的静态资源到本地(多用于解决第三方的问题),重新创建一套https的资源,让http和https指向各自的服务器;
2、用同一套代码,由nginx代理转发http和https到相同的静态资源,这要求两个协议处于同一服务; Continue reading "https访问http加载不出图片资源的问题分析"
浩克下载是针对安卓Android超强引擎磁力、种子下载器,无视版权和冷门,拒接下载无速度!(死种子除外)
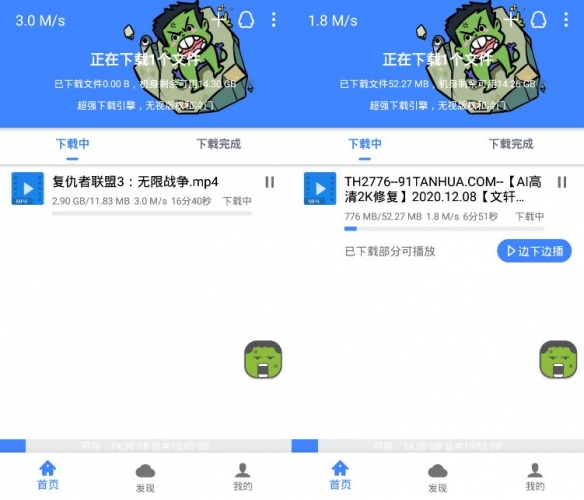
浩克下载 介绍:
非常好用的万能磁力搜索神器,可以在这里搜索各种视频、软件、游戏等,所有资源都可以直接在线下载,下载速度非常快,并且所有资源全部都是免费的,内置多款知名搜索浏览入口
云播模式:特有的云播放模式,连接互联网资源库;
海量资源:所有视频资源统统免费,任你点播,免费观看。 Continue reading "浩克下载V1.08 For Android支持BT/eMule/Magnet/FTP/HTTP/Thunder等链接"
EagleGet(EG Download Accelerator,中文名:猎鹰)是一个用于 Windows 系统的下载管理器,支持HTTP、P2P、Ed2k、Magnet等。EagleGet是一款国外新秀免费下载工具,与越来越凌乱臃肿、偏离下载软件初衷的迅雷不同,EagleGet 有着简洁、清爽的界面,它专注于提高下载速度与提升下载体验。

EagleGet 使用多线程技术,支持从Youtube、Dailymotion、Facebook、Vimeo等视频网站 Continue reading "迅雷替代神器:猎鹰EagleGet 最新版官方下载"
Fiddler是一个http协议调试工具,它能够记录并检查所有你的电脑和互联网之间的http通讯,实现数据的抓包;且可以设置断点,查看所有的“进出”Fiddler的数据(指cookie,html,js,css等文件)。 Fiddler 要比其他的网络调试器要更加简单,因为它不仅仅暴露http通讯还提供了一个用户友好的格式。
Fiddler还可以通过设置,直接抓取手机等移动设别在同一局域网内的数据,这样方便Android或者iOS等的数据抓包,通过安装证书实现SSL下也能调试数据,非常强大和方便。
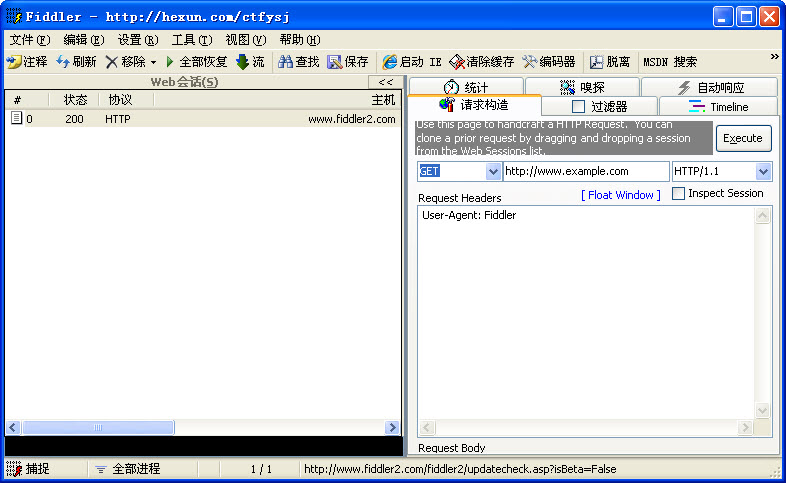
Fiddler 4 官方下载地 Continue reading "抓包利器:Fiddler 配置使用教程及下载"
我截获下来一个URL的字符串格式是“http%3A%2F%2F”,但是实际应该是http://
而“%2F”对应的就是 /
如果仅仅是想把字符串http%3A%2F%2F转换成http://的话,用strstr()等字符串系列函数应该可以解决吧
对于“http%3A%2F%2Fwww.baidu.com%2Fasd%3Fa%3D123”这种特殊字 Continue reading "字符串“http%3A%2F%2F”转换成http://详解"
2095已删除内容
如果某项请求发送到您的服务器要求显示您网站上的某个网页(例如,用户通过浏览器访问您的网页或 Googlebot 抓取网页时),服务器会返回 HTTP 状态代码响应请求。
此状态代码提供关于请求状态的信息, 告诉 Googlebot 关于您的网站和请求的网页的信息。
一些常见的状态代码为:
200 - 服务器成功返回网页
404 - 请求的网页不存在
503 - 服务器暂时不可用
下面提供 HTTP 状态代码的完整列表。 点击链接可了解详情。 您也可以访问 HTTP 状态代码上的
W3C 页获取更多信息。
1xx(临时响应)
表示临时响应并需要请求者继续执行操作的状态代码。
代码
说明
100(继续)
请求者应当继续提出请求。 服务器返回此代码表示已收到请求的第一部分,正在等待其余部分。
101(切换协议)
请求者已要求服务器切换协议,服务器已确认并准备切换。
2xx (成功)
表示成功处理了请求的状态代码。
代码
说明
200(成功)
服务器已成功处理了请求。 通常,这表示服务器提供了请求的网页。 如果针对您的 robots.txt 文件显示此状态代码,则表示 Googlebot 已成功检索到该文件。
201(已创建)
请求成功并且服务器创建了新的资源。
202(已接受)
服务器已接受请求,但尚未处理。
203(非授权信息)
服务器已成功处理了请求,但返回的信息可能来自另一来源。
204(无内容)
服务器成功处理了请求,但没有返回任何内容。
205(重置内容)
服务器成功处理了请求,但没有返回任何内容。 与 204 响应不同,此响应要求请求者重置文档视图(例如,清除表单内容以输入新内容)。
206(部分内容)
服务器成功处理了部分 GET 请求。
3xx (重定向)
要完成请求,需要进一步操作。 通常,这些状态代码用来重定向。 Google 建议您在每次请求中使用重定向不要超过 5 次。 您可以使用网站管理员工具查看一下 Googlebot 在抓取重定向网页时是否遇到问题。 诊断下的
[url=http://www.google.com/support/webmasters/bin/answer.py?answer=35156]
网络抓取
[/url]
页中列出了由于重定向错误而导致 Googlebot 无法抓取的网址。
代码
说明
300(多种选择)
针对请求,服务器可执行多种操作。 服务器可根据请求者 (user agent) 选择一项操作,或提供操作列表供请求者选择。
301(永久移动)
请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。 您应使用此代码告诉 Googlebot 某个网页或网站已永久移动到新位置。
302(临时移动)
服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。 此代码与响应 GET 或 HEAD 请求的 301 代码类似,会自动将请求者转到不同的位置,但您不应使用此代码来告诉 Googlebot 某个网页或网站已经移动,因为 Googlebot 会继续抓取原有位置并编制索引。
303(查看其他位置)
请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。 对于除 HEAD 之外的所有请求,服务器会自动转到其他位置。
304(未修改)
自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容。
如果网页自请求者上次请求后再也没有更改过,您应当将服务器配置为返回此响应(称为 If-Modified-Since HTTP 标头)。 由于服务器可以告诉 Googlebot 自从上次抓取后网页没有变更,因此可节省带宽和开销。
305(使用代理)
请求者只能使用代理访问请求的网页。 如果服务器返回此响应,还表示请求者应使用代理。
307(临时重定向)
服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。 此代码与响应 GET 和 HEAD 请求的 301 代码类似,会自动将请求者转到不同的位置,但您不应使用此代码来告诉 Googlebot 某个页面或网站已经移动,因为 Googlebot 会继续抓取原有位置并编制索引。
4xx(请求错误)
这些状态代码表示请求可能出错,妨碍了服务器的处理。
代码
说明
400(错误请求)
服务器不理解请求的语法。
401(未授权)
请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。
403(禁止)
服务器拒绝请求。 如果您在 Googlebot 尝试抓取您网站上的有效网页时看到此状态代码(可以在 Google 网站管理员工具诊断下的网络抓取页面上看到此信息),可能是您的服务器或主机拒绝 Googlebot 访问。
404(未找到)
服务器找不到请求的网页。 例如,对于服务器上不存在的网页经常会返回此代码。
如果您的网站上没有 robots.txt 文件,而您在 Google 网站管理员工具
[url=http://www.google.com/support/webmasters/bin/answer.py?answer=35237]
"诊断"标签的 robots.txt 页
[/url]
上看到此状态,那么这是正确的状态。 但是,如果您有 robots.txt 文件而又看到此状态,则说明您的 robots.txt 文件可能命名错误或位于错误的位置 (该文件应当位于顶级域名,名为 robots.txt)。
如果对于 Googlebot 尝试抓取的网址看到此状态(在"诊断"标签的 HTTP 错误页上),则表示 Googlebot 追踪的可能是另一个页面的无效链接(是旧链接或输入有误的链接)。
405(方法禁用)
禁用请求中指定的方法。
406(不接受)
无法使用请求的内容特性响应请求的网页。
407(需要代理授权)
此状态代码与 401(未授权)类似,但指定请求者应当授权使用代理。 如果服务器返回此响应,还会指明请求者应当使用的代理。
408(请求超时)
服务器等候请求时发生超时。
409(冲突)
服务器在完成请求时发生冲突。 服务器必须在响应中包含有关冲突的信息。 服务器在响应与前一个请求相冲突的 PUT 请求时可能会返回此代码,同时会附上两个请求的差异列表。
410(已删除)
如果请求的资源已永久删除,服务器就会返回此响应。 该代码与 404(未找到)代码相似,但在资源以前存在而现在不存在的情况下,有时会用来替代 404 代码。 如果资源已永久删除,您应当使用 301 指定资源的新位置。
411(需要有效长度)
服务器不接受不含有效内容长度标头字段的请求。
412(未满足前提条件)
服务器未满足请求者在请求中设置的其中一个前提条件。
413(请求实体过大)
服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。
414(请求的 URI 过长)
请求的 URI(通常为网址)过长,服务器无法处理。
415(不支持的媒体类型)
请求的格式不受请求页面的支持。
416(请求范围不符合要求)
如果页面无法提供请求的范围,则服务器会返回此状态代码。
417(未满足期望值)
服务器未满足"期望"请求标头字段的要求。
5xx(服务器错误)
这些状态代码表示服务器在尝试处理请求时发生内部错误。 这些错误可能是服务器本身的错误,而不是请求出错。
代码
说明
500(服务器内部错误)
服务器遇到错误,无法完成请求。
501(尚未实施)
服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码。
502(错误网关)
服务器作为网关或代理,从上游服务器收到无效响应。
503(服务不可用)
服务器目前无法使用(由于超载或停机维护)。 通常,这只是暂时状态。
504(网关超时)
服务器作为网关或代理,但是没有及时从上游服务器收到请求。
505(HTTP 版本不受支持)
服务器不支持请求中所用的 HTTP 协议版本。
已更新 12/4/2008
原文地址:
http://www.google.com/support/webmasters/bin/answer.py?answer=40132